架构师也需要在算法和数据结构上有坚实的基础。需要对以下主题有基本的了解才能开始:
了解数组,链表,二叉树,哈希表,图,堆栈,队列,堆和其他基本数据结构。
如果想精通算法,需要从几个不同的领域中了解一些数学概念。 集合论Set Theory,有限状态机finite-state machines,正则表达式regular expressions,矩阵乘法matrix multiplication, 按位运算bitwise operations,求解线性方程式linear equations,重要的组合概念combinatorics,例如排列permutations,组合combinations,信鸽原理。
了解如何在计算机中表示数据,数字逻辑设计,布尔代数,计算机算术,浮点表示,高速缓存设计的基础知识。尝试并学习一些有关C和汇编语言的知识。
对上面列出的大多数概念有了充分的了解后,就开始研究算法部分。为了更好地编写和理解重要算法而做的资源和工作的清单:
了解什么是Big-O,以及如何分析算法的运行时间。
实现一些基础算法并分析复杂度
500-Data-Structures-and-Algorithms-interview-questions-and-their-solutions
想在算法上做得更好,这是一个非常重要的概念,所以这里将本主题与其他主题分开特别来说: Dynamic Programming是一种解决复杂问题的方法,是将其分解为较简单的子问题的集合,仅解决一次这些子问题,然后存储其解决方案, 下一次出现相同的子问题时,无需重新计算其解决方案,只需查找先前计算的解决方案即可,从而节省了计算时间。 动态规划的问题在LeetCode,Google Code Jam等网站上有很多题目可以练习,而在Google Foo Bar上的一些问题则需要高级的DP解决办法。 在TopCoder上还有一个很好的教程,标题为:《动态编程-从新手到高级》。 许多DP问题具有相同的结构和模式,因此,如果在2周左右的时间内,每天解决3个DP问题,那么一段时间后基本上就可以对DP问题成竹在胸。
数据库(关系和非关系DB)如何在内部存储数据是个庞大,复杂的主题。我们谈论数据库内部存储时,许多人可以想象B树或B+树等,因为我们在大学或大学期间可能已经听说过这些。
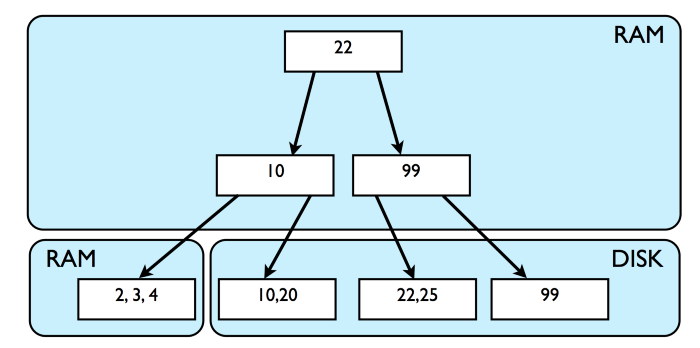
传统的关系数据库将数据存储在磁盘上的B+树结构中,它们还维护对这些树结构中的这些数据的索引(主要是在RAM中),以确保更快地访问原始数据。 用户插入的行存储在B+树的叶子节点处。所有中间节点都用于存储元数据,以在B+树中进行CRUD查询。 因此,当数据库中有数以百万计的行时,索引和数据存储的大小很有可能非常巨大了。 因此,为了提高效率,如果想将数据从磁盘加载到内存,则不能这样做,因为的RAM可能空间不足。所以,这时候数据库被迫从磁盘读取数据。
磁盘I/O成本很高,决定数据库性能。 B+树是随机读取/写入,就地替换,非常紧凑且具有自平衡功能的数据结构,它受到磁盘I/O限制。 随机访问意味着要访问磁盘上的某些数据,因此磁盘管理器必须将磁头移动到旋转的磁盘周围,因此这个操作很昂贵。 B+树以块形式存储数据,因为它对于操作系统以块形式读写数据,而不是写入单个字节,这会有效很多。 MySQL InnoDB数据库引擎的块大小为16KB。这意味着每次向数据库读取或写入数据时,都会将大小为16KB的磁盘页面块从磁盘中提取到RAM中,并将对其进行操作, 然后根据需要再次写回到磁盘中。 B+树利用了这种面向块的操作。 假设一行的平均大小为128字节(实际大小可能有所不同),那么大小为16 KB的磁盘块(在这种情况下为叶节点)最多可以存储(16 * 1024)/ 128 = 128行。 这只是粗略的估计,仅表明磁盘块可以容纳多行。 B+树是一个宽而浅的数据结构,通常高度≤10,在这种排列中可以包含数百万个数据。 由于这些性质,B树适用于数据库。如前所述,B+树的叶子位于同一级别,需要O(logN)的复杂度在B树中按主键排序的数据进行搜索。
因此,由于B+树必须遍历很少的节点并且触发很少的磁盘I/O调用,因此读取操作相对非常快。 当在同一页块中找到要获取或操作的行并且该页块已加载到内存中时,范围查询的执行速度也会更快。
还可以通过以下方式使基于B+树的数据库的执行速度更快:
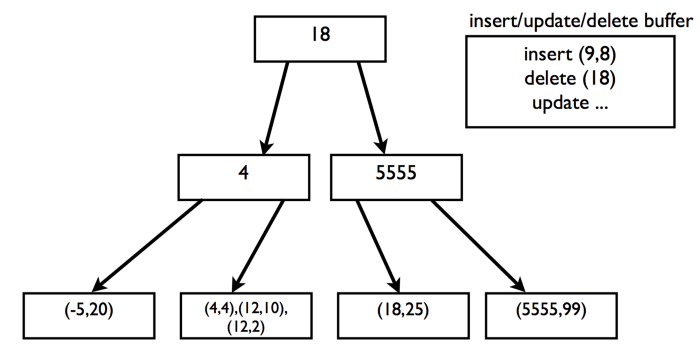
如果所需的叶节点不在内存中,则InnoDB缓冲区将插入,删除和更新。当缓冲区已满或相应的叶节点进入内存时,将刷新此缓冲区。
关系数据库系统内部也非常复杂,因为它们使用锁定,并发,ACID事务语义等,这使得读写操作更加复杂。 在现代信息时代,以消费者为中心的服务(如消息传递/聊天/实时通信/ IOT服务或面向非结构化数据的大型分布式系统)每小时可能发生数百万至数十亿次写操作。 所以,这些系统是高写入需求的系统,为了满足其需求,数据库应该能够赶上数据插入和检索速度。 关系型数据库不太合适这种情况,因为它们不满足高可用性,最后的选择大部分是所谓的最终一致性,非结构化数据定义的灵活性和允许一定程度的延迟等。
与B+ Tree稍有不同,FTI将每个block从中分一部分用作buffer,假设每个block size 为B,现在每个内部节点拥有K个子节点(k可以等于根号下B),则FTI的高度为O((log N/B)/(log K))
写放大:当root的buffer满了之后,需要将buffer中的records推到子节点的buffer中,一般情况下,每个子节点收到B/K个records,也就是说每B/K个records产生一次I/O,也就是写入B,那么每一个record产生K/B次I/O,也就是写入K,同样一条record,每往下推一层就产生K/B次I/O,写入K,所以一共写入O(K(log N/B)/(log K)),即写放大为O(K(log N/B)/(log K))
读放大:同B+ Tree一样,和树的高度相关,不过此时的高度为O((log N/B)/(log K)),即读放大为O((log N/B)/(log K))
LSM不像B/B+树这样的数据结构,它没有就地替换数据,即:一旦将数据写入磁盘中的某个部分,就永远不会对其进行修改。某些日志结构化文件系统(例如ext3 / 4)以这种方式工作。 而LSM在某个地方按一定顺序记录数据并利用顺序写入的优势。传统的磁性硬盘驱动器可以以每秒100 MB的速度写入数据,而现代的SSD驱动器可以以顺序的方式写入更多数据。 其中SSD驱动器具有某种内部并行机制,它们可以一次将16到32MB的数据一次写入在一起。 LSM树就非常适合SSD。在磁盘上顺序写入数据要比随机写入快很多,很好地支持高速和海量数据写入。 LSM的一个例子是Facebook发明的列式数据库Cassandra,根据LSM原理工作的。
Cassandra或别的LSM系统都维护一个或多个内存数据结构(在映像内存表中),例如AVL树,红黑树,B/B+树或跳表,并在将数据移到磁盘之前先写入数据。 此内存数据结构维护排序的数据集。 不同的LSM实现可能不用,并没有标准的LSM实现。当可存储内容超过可配置的阈值时,可存储数据将放入队列中以更新到磁盘。
为了更新数据,Cassandra将已排序的数据顺序写入磁盘。磁盘维护着一种称为“SSTable”或“Sorted Strings Table”的数据结构,这种结构是写入文件的数据的排序快照。 SSTable是不可变的。 LSM系统可以在磁盘上维护多个此类文件。 因此,如果在memtable中找不到数据,Cassandra就会扫描所有磁盘上的SSTable,因为数据可能分散在所有SSTable中。因此,Cassandra的读取在逻辑上比写入要慢。 针对读取操作比较慢的问题, Cassandra在后台连续运行压缩过程,最大程度减少此类SSTable的数量。 压缩过程实质上是对SSTable应用归并排序,然后将新排序的数据写入新的SSTable中,然后删除旧的SSTable。 但是有时侯压缩过程无法赶上数据库中发生的数据更新速度,所以某些数据结构(例如Bloom filter)被用于了解是否在恒定时间内SSTable中存在某些数据。
布隆过滤器在RAM中时会很有帮助,因为布隆过滤器内部会触发许多随机查询,以便获得有关数据存在的概率性。 布隆过滤器可以显著减少遍历所有SSTable的工作量,尽管有人说布隆过滤器在范围查询中没用处。 无论如何,为了提高读取速度,LSM系统保留了许多内部的解决方法,例如上面说的布隆过滤器。 因此,LSM系统解决了以极快的速度写入大量数据的问题,但可能无法以最佳速度检索数据。 LSM系统在大量数据读取时的问题 — 读取的数据多于实际需要的数据。那么,在B/B+树和LSM树之间是否可以进行取舍进行实现,从而提供最佳和边际递增的读写速度呢?