Apache Spark是一个框架,可让让使用者立即分析数据并主要执行内存中的计算。此外,Spark还可以单独或与Hadoop/YARN等结合使用。这些因素导致许多人宣布Hadoop即将消失,并认为Sparks是其永久替代品。实际上,就Hadoop而言,借助MapReduce的增强功能,它可以首先在处理信息之前先存储所有信息。由于它跟Spark比速度不占优势,但可用于处理内存量很小的大量数据,所以仍是很有用的。Spark则使用内存中数据处理,这意味着它将占用大量内存,因为在处理完成之前将需要大量数据缓存。因此,在选择Spark之前,需要确保有足够的内存。
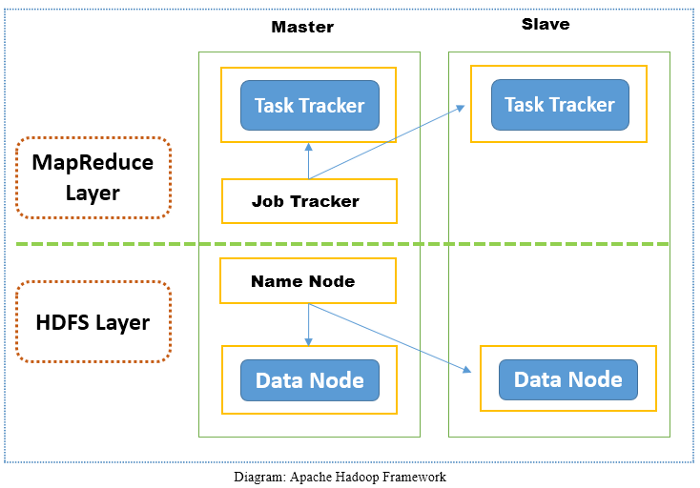
Apache Hadoop是一个开放源代码软件框架,旨在从单个服务器扩展到数千台机器,并在商用硬件群集上运行应用程序。 Apache Hadoop确实做得很好。它也一直在发展并逐渐成熟,具有新的特性和功能,以使其易于设置和使用,目前最新版本是3.x,Hadoop现在已经有一个庞大的应用程序生态系统。 Apache Hadoop框架分为两层。第一层是存储层,称为Hadoop分布式文件系统(HDFS),第二层是处理层,称为MapReduce。 Hadoop的存储层,即HDFS负责存储数据,而MapReduce负责处理Hadoop Cluster中的数据。
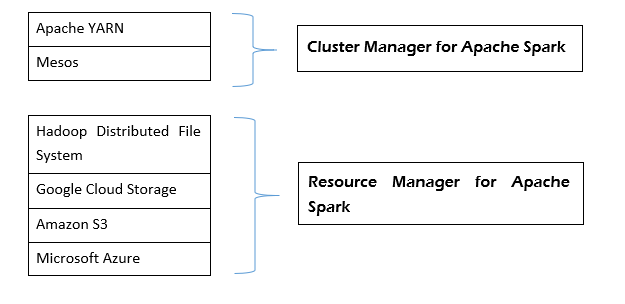
Apache Spark是一个非常快的集群计算技术框架,旨在用于大规模数据处理的快速计算。 Apache Spark是一个分布式处理引擎,但是它没有内置的群集资源管理器和分布式存储系统,所以必须引入的集群管理器和存储系统。
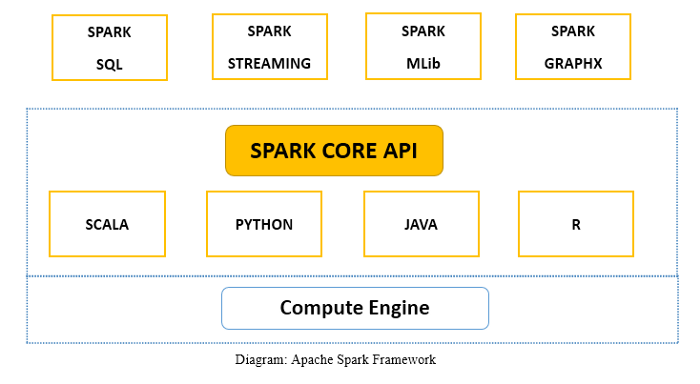
Apache Spark框架由Spark Core和库组成。 Spark core通过为最终用户提供无缝体验来执行和管理工作。用户必须将作业提交给Spark core,Spark core负责进一步的处理,执行并回复用户。我们可以选择使用不同脚本语言(例如Scala,Python,Java和R)来调用Spark Core API。另外Apache Spark是用于批处理和流模式的数据处理引擎,具有SQL查询,图处理和机器学习功能。
尽管Hadoop和Spark之间有所区别,Spark比Hadoop更快,但实际中应用还是得看场景。乍看之下,Spark是比Hadoop更好的新版本,但事实并非如此,最好对大数据和Hadoop进行更深入的研究,以确定是否合适。需要考虑项目的具体应用场景和员工的知识背景。
另外,值得注意的是,很多时候可以不必选择,可以同时使用两者。 Spark与Hadoop完全兼容,并且也与分布式文件系统HDFS很好地兼容。通过将两个框架一起使用,可以获得更快的分析速度,优化的成本以及避免重复。