互联网产品的特点可以说有以下:
等等,互联网应用实现高性能,高可用,可扩展和可伸缩就非常重要了。这几个指标分别来看看定义:
一般需要满足四个9。不同层级使用的策略不同,一般采用冗余备份和失效转移解决高可用问题:
另外安全性和敏捷性也需要额外考虑。
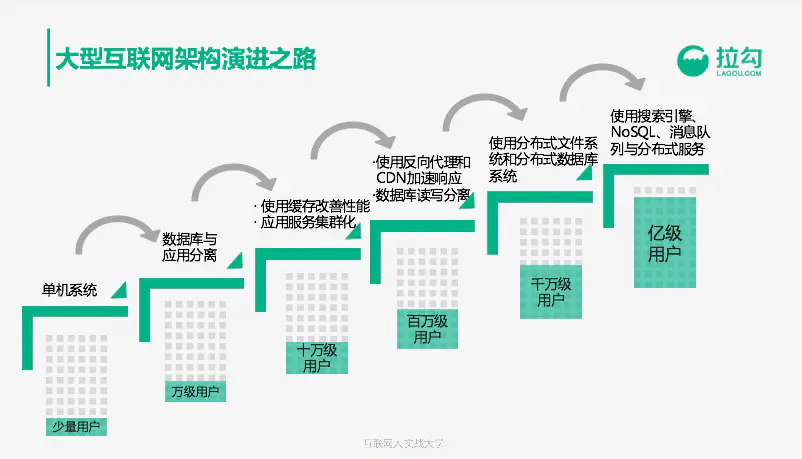
演进模式可以根据这篇文章支撑亿级用户的大型互联网架构:从0到1的演化过程来学习。
这个文章分别从单机系统(一个应用服务器,几百个用户)->数据库与应用程序分离(应用程序和数据库分开部署,万级用户)->使用缓存改善性能(分布式缓存,本地缓存,十万级别)->使用反向代理,CDN,DB读写分离等(百万级别)->分布式文件系统和分布式数据库(千万级别)->使用搜索引擎,NoSQL,消息队列和分布式服务(亿级用户)
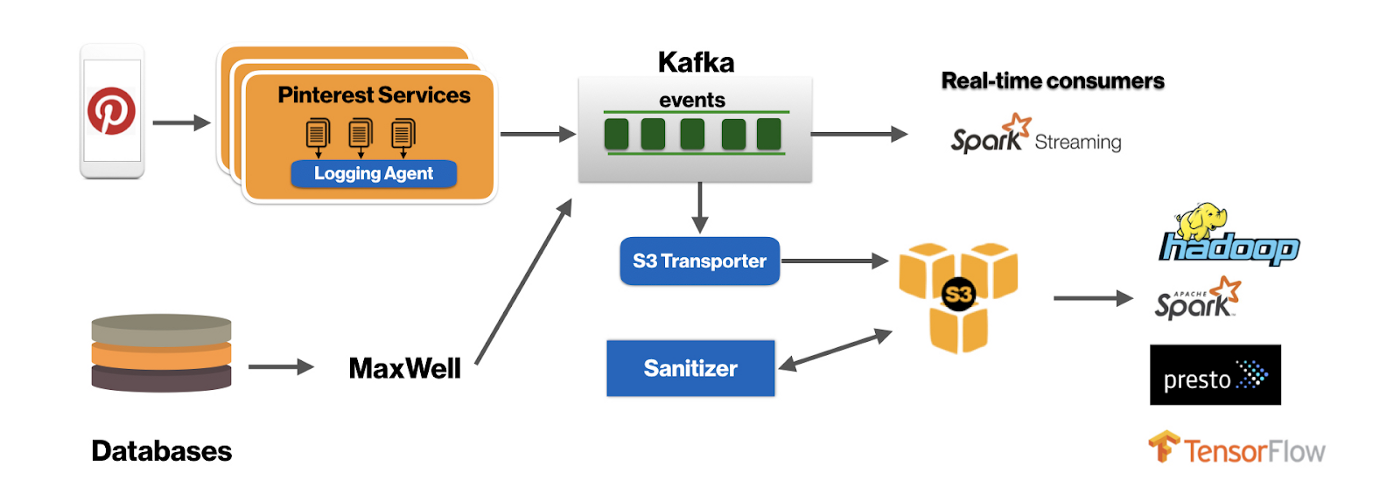
在云上运行时的基本原则之一是确保应用程序的高可用。 实现此目的的一种常见方法是将应用程序的部署分布在多个故障域(Failure Domain)中。 在公共云环境中,可用区(Availability Zone, AZ)可以用作故障域。我们可以使用多个可用区来为应用程序提供容错能力。 像HDFS这样的分布式系统传统上是使机架感知的,以通过在数据中心内的多个机架之间分布副本来提高容错能力。 但是,在云环境中运行时,通常将AZ用作机架信息。这样就可以将数据副本分布在多个可用区中,从而在出现故障的情况下提供容错能力。尽管跨可用区复制数据可提供容错能力,但以可用区传输成本的形式确实要付出额外的代价。 在Pinterest,我们广泛地将Kafka用作可伸缩的,容错的分布式消息总线,以为诸如用户动作计数和更改数据捕获(CDC)之类的关键服务提供动力。由于我们的Kafka规模很大,因此我们需要注意AZ传输成本并尽可能高效地运行,因此我们专注于减少跨AZ传输的数据量。
当Kafka集群的代理分布在多个可用区中时,会导致三种类型的交叉可用区网络流量:
在上述三种流量类型中,我们需要1,以实现容错;但是,2和3是不希望有的副作用,会引起额外的成本,从理论上讲,这些成本可以消除。如下:
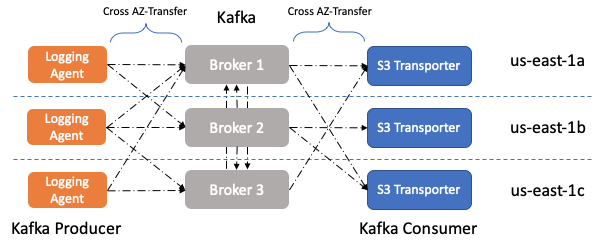
有两种潜在的方法可以解决此问题。
我们只能让生产者和消费者为领导者共享相同可用区的分区写入/读取数据,以使其更具成本效益。
另外,我们可以部署AZ特定的Kafka集群,但是要实现这一点,任何其他实时消费者都需要使他们的业务逻辑AZ知道。 为了简单起见,我们选择采用方法1,因为它最小化了代码和堆栈更改。通过查找我们要读取/写入的分区的领导者经纪人的机架信息,并更改生产者和消费者的分配逻辑,可以实现生产者/消费者AZ意识。 在Kafka中,经纪人的机架信息是PartitionInfo元数据对象的一部分,该对象与Kafka客户(消费者和生产者)共享。因此,我们在Kafka集群中部署了机架感知功能,每个代理在该集群中将其所在的可用区作为节点机架信息发布。 我们从针对Kafka,测井代理和S3运输机的最大生产者和消费者应用程序开始了这项计划。
最后的设计